
Research Log #047
Welcome to Research Log #047! We document research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
Manifold Updates
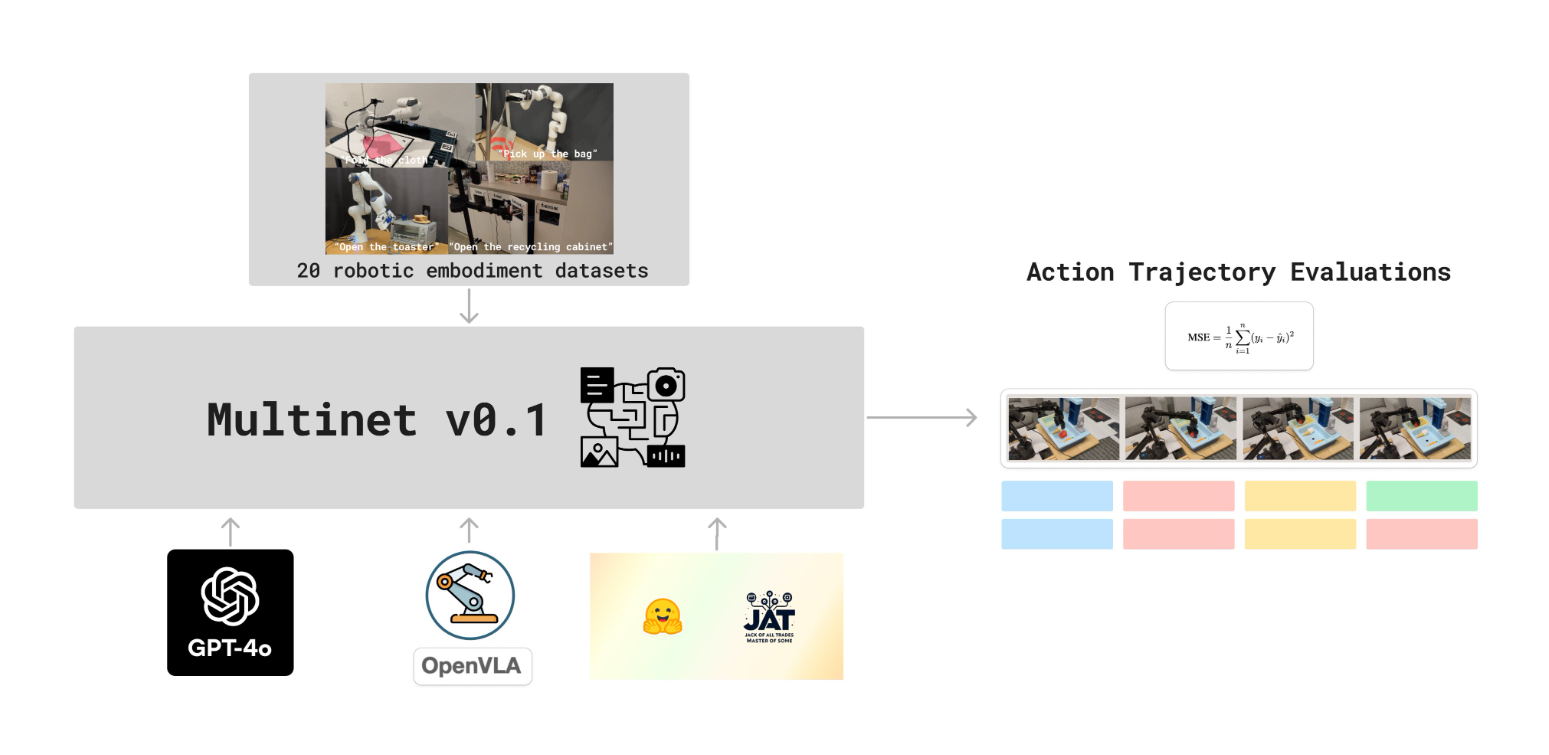
MultiNet: This week, we released MultiNet v0.1, accompanied by papers, a website, and open-source code! Additionally, we completed the evaluation of GPT-4o, JAT, and OpenVLA on 20 OpenX Embodiment datasets, providing comprehensive insights into their performance. Our analysis of the results is now finalized, highlighting key findings and opportunities for future research.
Multimodal Action Models: μGato is our streamlined implementation of DeepMind's Gato paper, designed with clarity, simplicity, and experimentability in mind. It features a detailed Jupyter notebook that walks through the paper page-by-page, constructing the architecture from scratch for maximum understandability. The alpha version has already completed its first successful training run, leveraging 4 mini-datasets across text, vision/question answering, and discrete+continuous robotics tasks.
Metacognition in Robotics: We’ve continued our deep dive into the latest research on calibration, focusing on understanding recent advancements in the field. Our efforts included replicating state-of-the-art methods to validate and build on existing findings. Additionally, we collaborated with TogetherAI to troubleshoot and resolve a bug in their API, reinforcing our commitment to fostering innovation through teamwork and technical expertise. More information is available in our Discord channel!
Swarm Assembly of Modular Space Systems: Our team has broken the swarm assembly problem into several key subsections: identifying conflict-free sub-structures, assigning tasks to agents, and planning paths for those agents. We’ve made progress in task assignment, with efforts now focused on developing methods for identifying conflict-free sub-structures and optimizing path planning. You can see all of the literature we’re reviewing on our public zotero.
Generative Biology: Our ongoing efforts include an extensive literature review and alignment on key research directions to guide future work. We are actively analyzing BioML model performance and profiling open-source datasets to uncover insights and opportunities. With progress on these fronts, we are tracking toward optimizing an open-source model to significantly enhance performance within the next few months. Stay tuned via our Generative Biology discord channel!
Pulse of AI
Large Language Models Can Self-Improve in Long-Context Reasoning:
Recent advancements in large language models (LLMs) have enhanced their ability to process extended contexts, but there remain challenges with reasoning in long-contexts. To address this, researchers have introduced SeaLong, a novel approach enabling LLMs to self-improve in long-context reasoning tasks. SeaLong works by generating multiple outputs for each query, evaluating them using Minimum Bayes Risk scoring before fine-tuning the model based on these outputs. This method has demonstrated significant performance enhancements, notably a 4.2-fold improvement for Llama-3.1-8B-Instruct, exceeding previous techniques that relied on human annotations or advanced models. The success of SeaLong indicates a promising direction for self-improvement strategies in LLMs, especially for applications requiring complex reasoning over extended contexts. For those interested in the technical details, the paper is available here.
Add-It: Training-Free Object Insertion in Images With Pretrained Diffusion Models:
In the world of image editing, integration of new objects into existing scenes poses significant challenges, especially when needing to maintain realism without extensive retraining. To address this, researchers at Nvidia have introduced Add-It, a novel framework that leverages pretrained diffusion models to insert objects into images without the need for additional training. Add-It operates by guiding the diffusion process to incorporate new elements while preserving the original image’s context and aesthetics. This enables users to add objects into images without needing to train anything, ensuring the inserted elements blend naturally with the existing scene. The effectiveness of Add-It has been demonstrated across various use cases, showcasing its potential as a versatile tool for image editors. The full paper is here.
OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models:
The development of high-quality code from large language models (LLMs) has been hindered by limited access to high-quality training data and transparent training methodologies. To address this, researchers have introduced OpenCoder, an open-source code LLM that rivals leading proprietary models in performance. OpenCoder’s edge is in providing not only the model weights and inference code, but also the reproducible training data, complete data processing pipeline, and detailed training protocols. This transparency enables more rigorous scientific investigation and replicable advancements in LLM-augmented code. OpenCoder serves as an “open cookbook,” empowering the research community to explore, adapt, and build on its framework, and helping to advance state-of-the-art in code generation and reasoning tasks. For more details, the full paper is here.
If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, and Linkedin!