

Welcome to Research Log #045! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
Manifold Updates
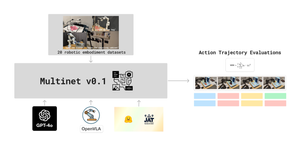
MultiNet: Profiling kicked off last week, and the profiling of JAT on the majority of the OpenX datasets is now complete. Results are available, and experiments are being tracked. GPT-4 profiling on OpenX is close to starting. Task, environment, and action space descriptions for the variety of OpenX datasets are being populated, finalizing the prompt engineering framework needed for profiling. Most of the codebase is complete and available on GitHub.
Multimodal Action Models: We're kicking off an investigation into a new class of models—Vision Language Action (VLA) models. We're scoping out how these models, designed to perform vision-language grounded robotics actions, can be adapted to function as regular Vision Language Models (VLMs) and evaluating their performance in this capacity.
Cooperative Robotics: The team is investigating the role of communication in swarm coordination, exploring different types of communication, their features, and what those features enable. In multi-agent systems, agents perform four key tasks: continuous cooperative tasks, discrete cooperative tasks, continuous allocation (e.g., resources), and discrete allocation (e.g., tasks). We plan to examine how swarms currently manage these tasks in the literature and where adaptation fits into each. Check out our public Zotero library here.
Generative Biology: We had our kickoff meeting on Sunday, reviewing key milestones, recruitment, and aligning on our research strategy. Weekly status meetings and ad-hoc sessions will follow. We're continuing our literature review on generative and synthetic biology, with a focus on medical applications. Our Zotero collection is available here. We're also defining an early-stage research question, such as fine-tuning a BioML model, to guide our long-term direction. Additionally, we're documenting BioML models and open-source datasets to support this work.
Pulse of AI
Seed-Music: A Unified Framework for High-Quality and Controlled Music Generation:
The creation of music is complex, involving multiple stages from composition to post-production. Enter Seed-Music, a new framework designed by ByteDance’s Seed Team to make music generation and editing more accessible, without putting quality at risk. This framework uses auto-regressive language models and diffusion techniques, enabling creators to generate vocal music with granular control over lyrics, style, and even specific aspects of music performance—this is enabled through multi-modal inputs like voice prompts or audio references. But it doesn’t stop there. Seed-Music also offers intuitive post-production tools for editing vocals, melodies, and timbres directly within existing tracks; this augments the ability of beginning and experienced producers alike. One of the most interesting features of Seed-Music is zero-shot singing voice conversion, enabling the generation of new vocal performances from just a 10-second recording! The full paper is here.
DrawingSpinUp: 3D Animation from Single Character Drawings:
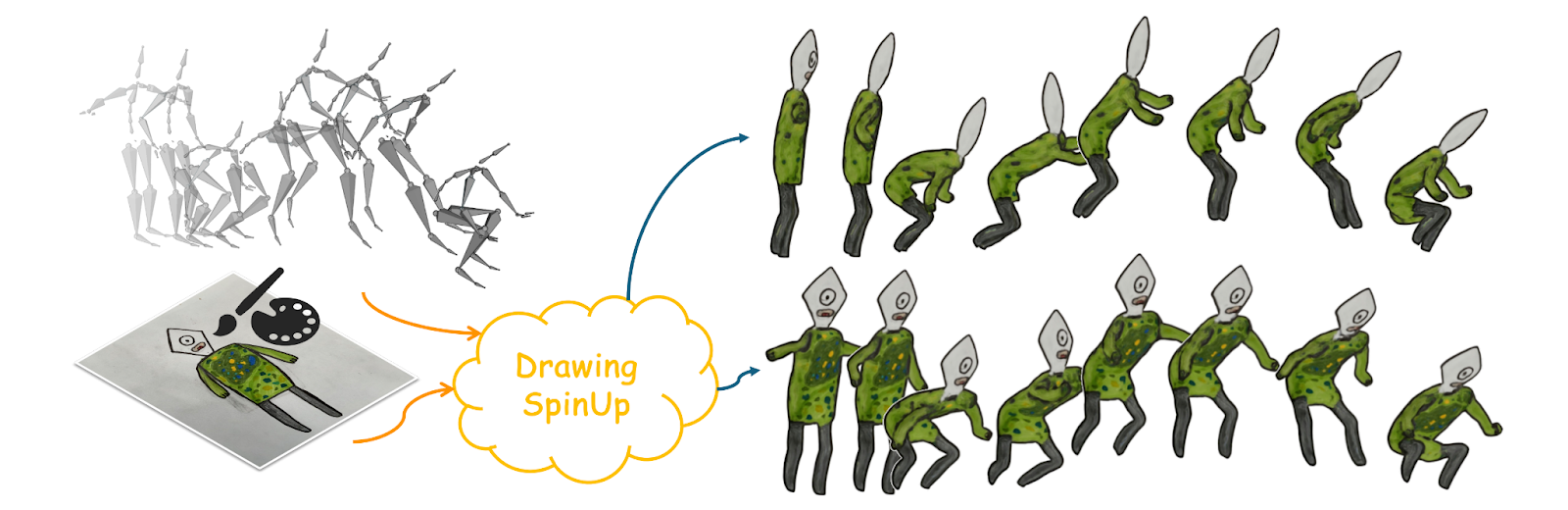
Bringing your hand drawings to life is a fun but challenging task, especially if you are a novice and charting the territory of 3D animation, which often requires expensive hardware and software, making it economically challenging for artists. DrawingSpinUp is a new system developed by researchers at the City University of Hong Kong, China, which is designed to address this gap, transforming simple character sketches into dynamic 3D animations which can rotate, leap, and even dance—all while maintaining the original style of the creator! Traditional image-to-3D methods have historically struggled in the processing of amateur drawings, especially when dealing with contour lines or thin, delicate structures like limbs of cartoon characters. DrawingSpinUp addresses these challenges by removing and then restoring view-dependent contour lines, ensuring accurate synthesis of textures and refining slim structures with a skeleton-based thinning algorithm. Through these novel methods, it is able to produce fully-animated 3D characters that outperform current 2D and 3D animation techniques. For those interested in the technical details, the paper is available here.
InfiMM-WebMath-40B: Advancing Multimodal Pre-Training for Enhanced Mathematical Reasoning:
Pre-training large language models (LLMs) in specific domains like mathematics has historically posed challenges, especially in multi-modal settings where inputs and outputs could be text or images. These challenges have been augmented by a lack of high-quality, open-source datasets which researchers from ByteDance and the Chinese Academy of Sciences have addressed through the establishment of a mathematical open-source dataset called InfiMM-WebMath-40B. This dataset has been sourced from CommonCrawl, including 24 million math-related web pages, 85 million image URLs, and 40 billion text tokens! Researchers integrated textual and visual data to address the multi-modal challenge, boosting the performance of LLMs fine-tuned on math reasoning tasks, outperforming existing datasets in text and multimodal evaluations. For more details, the full paper is here.
If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, Linkedin, and Mastodon!