

Welcome to Research Log #044! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
Manifold Updates
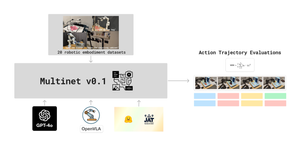
MultiNet: The datasets required for profiling have been downloaded and stored internally. We've also coded and open-sourced a method to translate several shards of control data to TFDS sequentially and automatically, resolving memory leakage issues with the tf.data.Dataset.save() method and circumventing RAM bottlenecks. Additionally, the train, validation, and test splits of the OpenX datasets have been successfully translated to TFDS and are ready for profiling.
Multimodal Action Models: The JAT codebase has been systematically modified and generalized to generate next actions for the majority of the OpenX tasks and datasets, based on inputs such as observation states, rewards, action space, language instructions, and image observations. The data loader and performance evaluation code are currently in progress. Additionally, the initial version of the prompt engineering framework to adapt state-of-the-art VLMs like GPT-4o to action trajectories in OpenX is complete. Work is underway to generalize this framework for zero-shot and few-shot capabilities across all OpenX tasks and datasets.
Metacognition in Robotics: The team is currently evaluating VLMs' calibration error and exploring strategies to reduce it. More information can be found in the discord channel here.
Cooperative Robotics: We’re in the midst of our literature review on how swarms of agents can adapt to real-time, unexpected changes in their environment and retain or recover mission success. The team is cataloging various approaches and has so far identified: Online Independent RL, Online Multi-Agent RL, and Embodied Evolution. Relevant papers can be found in our Zotero Public Library.
Foundation Models for Bio: The team is currently focused on a literature review as part of our weekly group meetings to understand the landscape of foundation models in biology applications and the state of AI in both medicine and synthetic biology today. As we scale up with additional research collaborators, we're mapping out the state-of-the-art (SOTA) performance of foundation models across the following modalities: DNA & Gene, RNA, Protein, Single-Cell, and Multimodalities. Relevant papers can be found in our Zotero Public Library.
Foundation Models for Math/CS: We’re holding our first meeting this Sunday with key participants to discuss the mission and scope of the project. During this meeting, we’ll also decide on the frequency and timing for recurring meetings. Check out the conversation here.
Pulse of AI
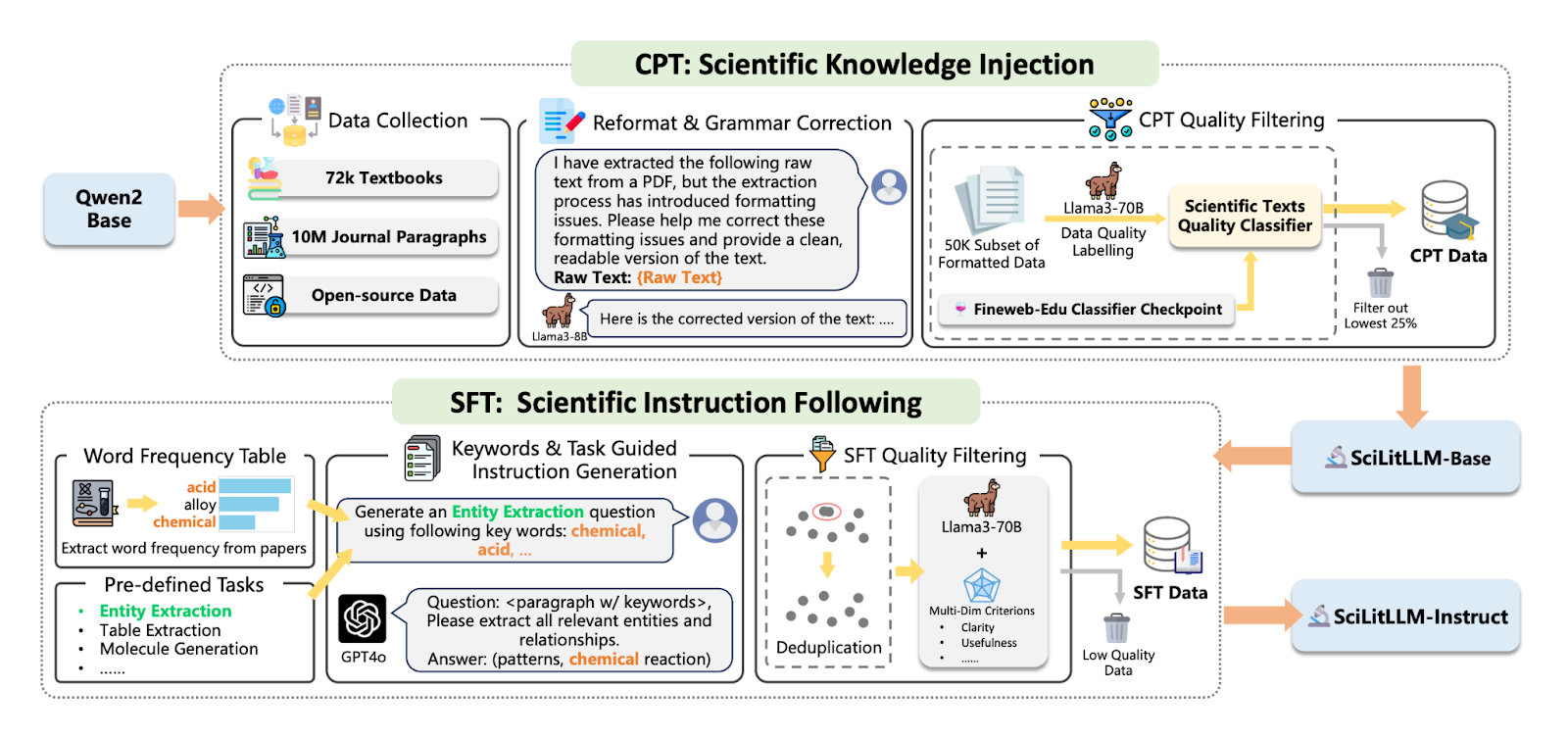
Adapting LLMs for Scientific Literature Understanding: Large language models have been used for a variety of applications, such as coding and tutoring. But how can they aid domain-specific understanding of scientific literature? This remains one of the high-yield applications of LLMs that has largely been unmet in the space due to gaps in domain-specific knowledge and task familiarity. To address this gap, researchers from the University of Science and Technology of China and DP Technology introduce a new model called SciLitLLM fine-tuned for scientific literature understanding via continual pre-training and supervised fine-tuning.
As a part of this investigation, researchers highlight some of the challenges of putting it together, such as the construction of high-quality datasets for CPT and generating diverse instructions for SFT, which they address through a novel pipeline (Figure 1). Key research contributions include the development of an adaptable architectural framework for training domain-specific LLMs, and a new instruction set (SciLitIns) for underrepresented scientific fields. Overall, SciLitLLM shows promising signs of improvement in terms of scientific literature tasks, such as molecular generation, entity and table extraction. The full paper is here.
Law of Vision Representation in Multimodal Large Language Models: Multimodal large language models (MLLMs) have made significant progress by integrating pretrained vision encoders with powerful language models. But selecting the best vision representation remains a challenge given the trial-and-error involved, with researchers often relying on empirical results rather than benchmarks. Researchers from Stanford and UC-Berkeley address the lack of understanding around why certain vision representations perform better than others through the Law of Vision Representation. As a part of this, they find model performance to be strongly correlated with cross-modal alignment and correspondence (AC) of the vision representation.
The alignment and correspondence score (AC score) is introduced to quantify this relationship, with a 95.72% linear correlation between AC score and model performance. This enables selection of the best vision representation without having to repeatedly fine-tune the language model, leading to a 99+% reduction in associated computational cost. They propose an AC policy which not only cuts down on the time and resources needed for testing vision encoders but which also expands the search space, driving efficiency and accuracy along the identification of optimal vision representations for MLLMs. For those interested in the technical details, the paper is available here.

If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, Linkedin, and Mastodon!