Welcome to Research Log #038! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
NEKO
The NEKO Project aims to build the first large scale, Open Source "Generalist" Model, trained on numerous modalities including control and robotics tasks. You can learn more about it here.
As mentioned way back in Research Log #031, the NEKO team has been dealing with a stagnated perplexity score during training. This week Bhavul, one of our NEKO team members, was able to fix this long standing issue for the text modality. He refactored the code as well; it can now run on a single GPU. The improvements to the text modality are contained within this branch of the repo. If you would like to help, send a message in our discord server!
MultiNet
MultiNet is creating an omni-modal pre-training corpus to train NEKO and Benchmark other MultiModal Models or Omni-Modal Models.
The MultiNet team focused on starting the new control port of the JAT dataset. We are also searching for alternatives for the LTIP dataset because the original replacement LION 2B was taken down because of ethical concerns. We are considering using WIT. If you would like to contribute, the GitHub repo is here.
Pulse of AI
This week, two different companies are making real time personal assistants. Google released a new model capable of generating video. A new version of one of the best protein folding models just dropped. And finally, a new alternative architecture has joined the race to try to replace the transformer.
GPT4o
OpenAI released a new version of their flagship model named GPT4-o the o stands for “omni” because it’s supposed to work across audio, vision and text in real time (side note, when Manifold says “omni-modal” we’re referring to performance over hundreds of task modalities). It’s an incredibly fast model capable of GPT-4 turbo performance with better capabilities in other languages besides English.
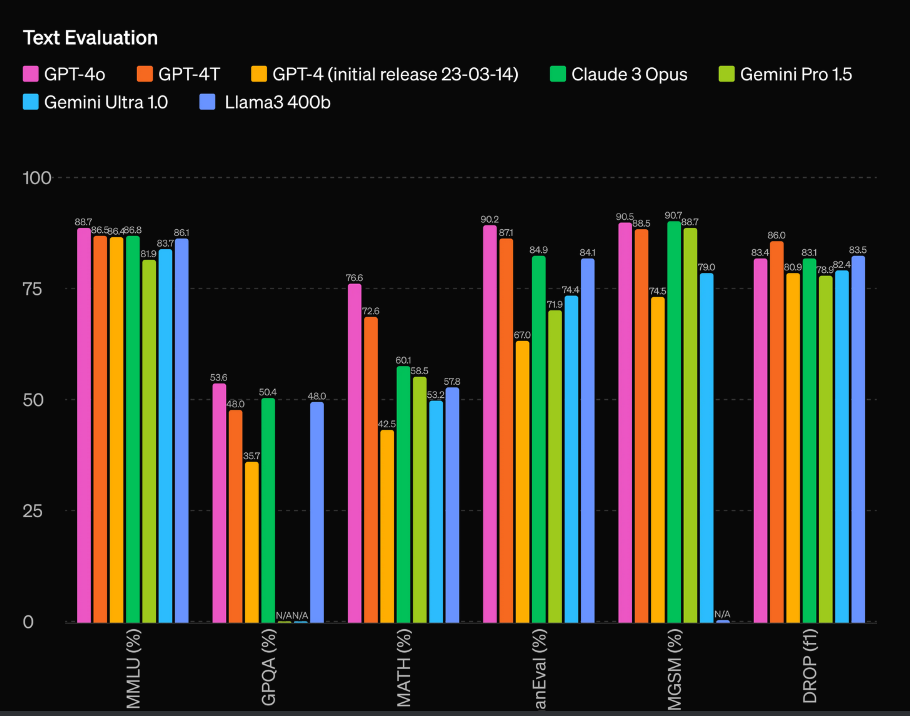
GPT4o is basically a little bit better or on par with GPT-4T (the current version). This release is not focused on improving the state of the art. It’s more focused on just making the model faster.
You should definitely check out some of the demos they released on twitter/X like this one or this thread. The voice intonation is getting really good, and it can do actual in real time translation.
If you would like to read a bit more about this new GPT-4o release, the blogpost is here.
Google I/O
With Google I/O there were a lot of releases that are coming in the following weeks and months. We can summarize into three main points: Gemini is getting a new model for personal assistance, Google released a new video model named Veo, their response to Sora from OpenAIand Imagen 3 is rolling out in the following months.


Gemini is getting a faster version with a new model named “Gemini Flash”. This model is made for “speed and efficiency”. The model has a one million token context window and it’s getting better throughout the year with an even bigger context window of 2 million tokens. The main focus of this model is to be capable of understanding video and audio in real time and is the clear competitor to GPT4o.
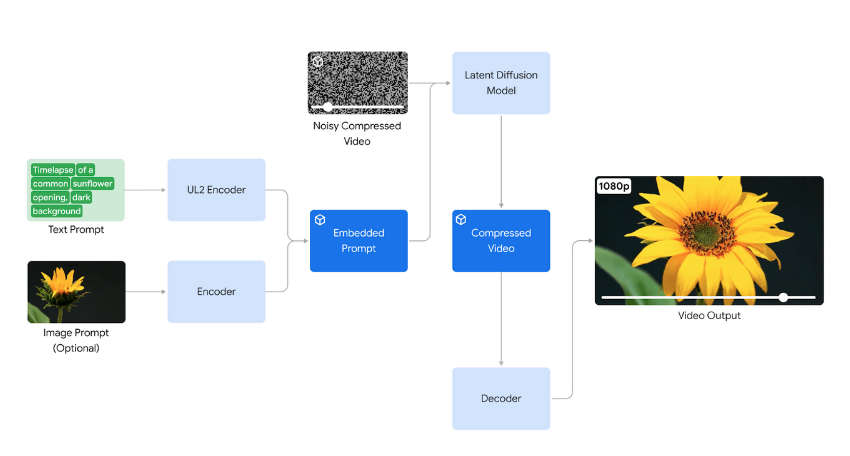
Veo is the new video model from Google DeepMind that builds upon the ideas of Lumiere and several other video models to generate high quality video from prompts that is consistent over time. The model is still not capable of generating humans as it seems from the test videos that they have shown but for stock footage it seems like a great first step.

Imagen3 is the new upgrade for their image generation model and it’s a nice improvement from the previous Imagen2. The main thing that it has is that it has fewer artifacts, it’s better at generating text and follows the prompt instructions even better than their last model.
If you would like to read about Gemini Flash, the release blog post is here. If you are more interested in the new video model, you can find the blogpost here. And finally, if you would like to read about the new upgrade for Imagen, the release is here. If you would like a summary of the entire Google I/O conference, a good summary is here.
AlphaFold 3

With AlphaFold 3, the protein folding model gets an upgrade to simulate DNA, RNA and Ligand structures. Now, it is possible to simulate basically everything that is a building block of life.

The way that it works is by inputting a sequence of molecules. Then, the model generates embeddings and the pairformer passes information to the diffusion module, like those that we see in Stable Diffusion or DALLE-3. The diffusion module perfects the protein and finally generates a possible generated protein structure.
If you would like to read more about protein folding, the original paper published in Nature is here and the release blogpost is here.
xLSTM
Originally, Recurrent Neural Networks were revolutionary. But they had two different pain points: the first one was gradient explosion where you train a model and the model suddenly has gradients so big that the neural network moves around in the problem space and doesn't learn a generalizable solution, the second one was the vanishing problem where the gradient becomes so small that the model stops learning. The first problem was solved by clipping the gradient. The second one was solved by LSTMs and GRUs, they solved it by adding a forget gate and generating the possibility of making the model just retain the relevant state. But, LSTMs and RNNs are still not adapted to be parallelizable through GPUs because they are dependent on the previous state to calculate the next one. This is where alternative takes on RNNs come in like RWKV, but now, we get a new version of LSTMs for the Transformer era.
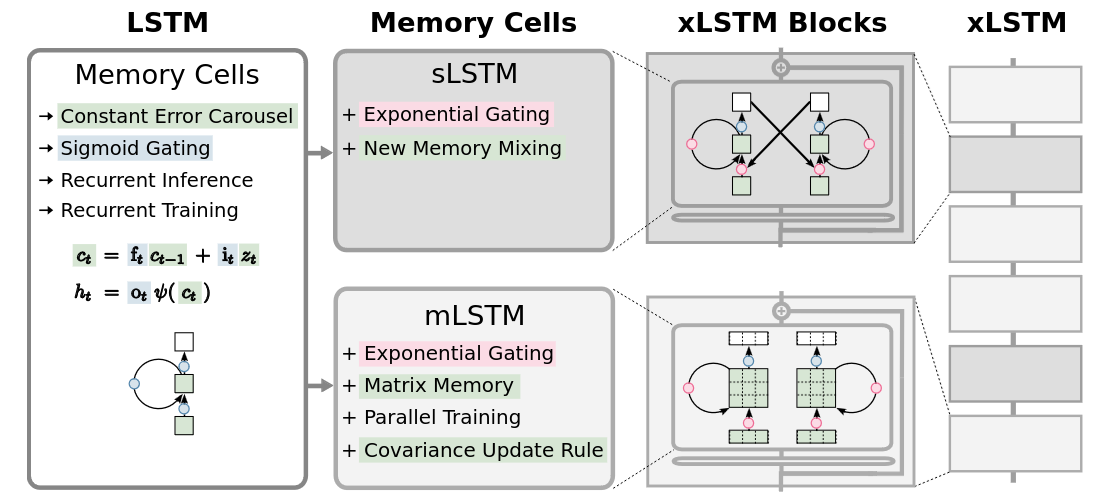
xLSTMs are composed of two different Memory Cells sLSTM and mLSTM. sLSTMs have exponential gating (literally just adding an exponential to the input and forget gate) and normalizing these values to not have them overflow memory. The other conceptually relevant idea is the Memory Mixing, where sLSTMs can have multiple memory cells where they can mix them via recurrence. mLSTMs are a bit bigger, they have Matrix Memory with a similar mechanism to the Attention Mechanism from the Transformer Architecture. The m variation also has exponential gating and it can be used for parallel training. A problem with this is that you still have the bottleneck of matrix multiplication for this architecture.
Finally the xLSTM block consists of mixing sLSTM and mLSTM blocks and adding them residually so that the connection can be learned only if necessary. They mixed and matched with. The results for xLSTMs seem to be pretty interesting.
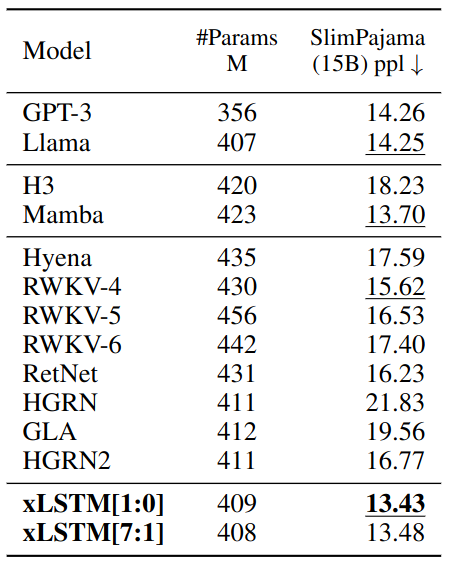
xLSTMs seem to be better at predicting the next token than either Transformers, RNNs or State Space Models. Although predicting the next token is not everything, it seems like it could potentially be an alternative to Transformers.

Here, we can see that it’s doing well against the past version of RWKV. We still don’t see the results against RWKV-5 or RWKV-6 and the Mamba Model still holds up in the 1.3 Billion parameter range. It would have been interesting to see a comparison against Recurrent-Gemma or Griffin in this space.
It’s great that we are starting to see more and more alternatives to transformers. If you would like to read the original paper, it is here.
That’s it for this week folks! See you next week.
If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, Linkedin, and Mastodon!