

Welcome to Research Log #036! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
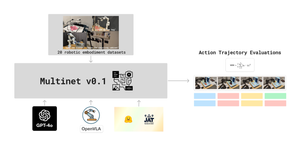
MultiNet
This week we’ve launched The MultiNet Project, which ultimately aims to create the first Massive Multi Modal Generalist Benchmark. The first version of the project is going to be a pretraining corpus for the NEKO project, which is important since we do not have access to all of the data that Google DeepMind had when training GATO, because most of it was close sourced. The team has put together a roadmap here, and if you are interested in contributing to this project, more can be found on the github for our benchmark here.
Pulse of AI
This week, Meta dropped the biggest model since GPT-4 and there is no reason why you would pay for a ChatGPT subscription now and we talk about understanding RNNs using the interpretability lens.
Llama 3
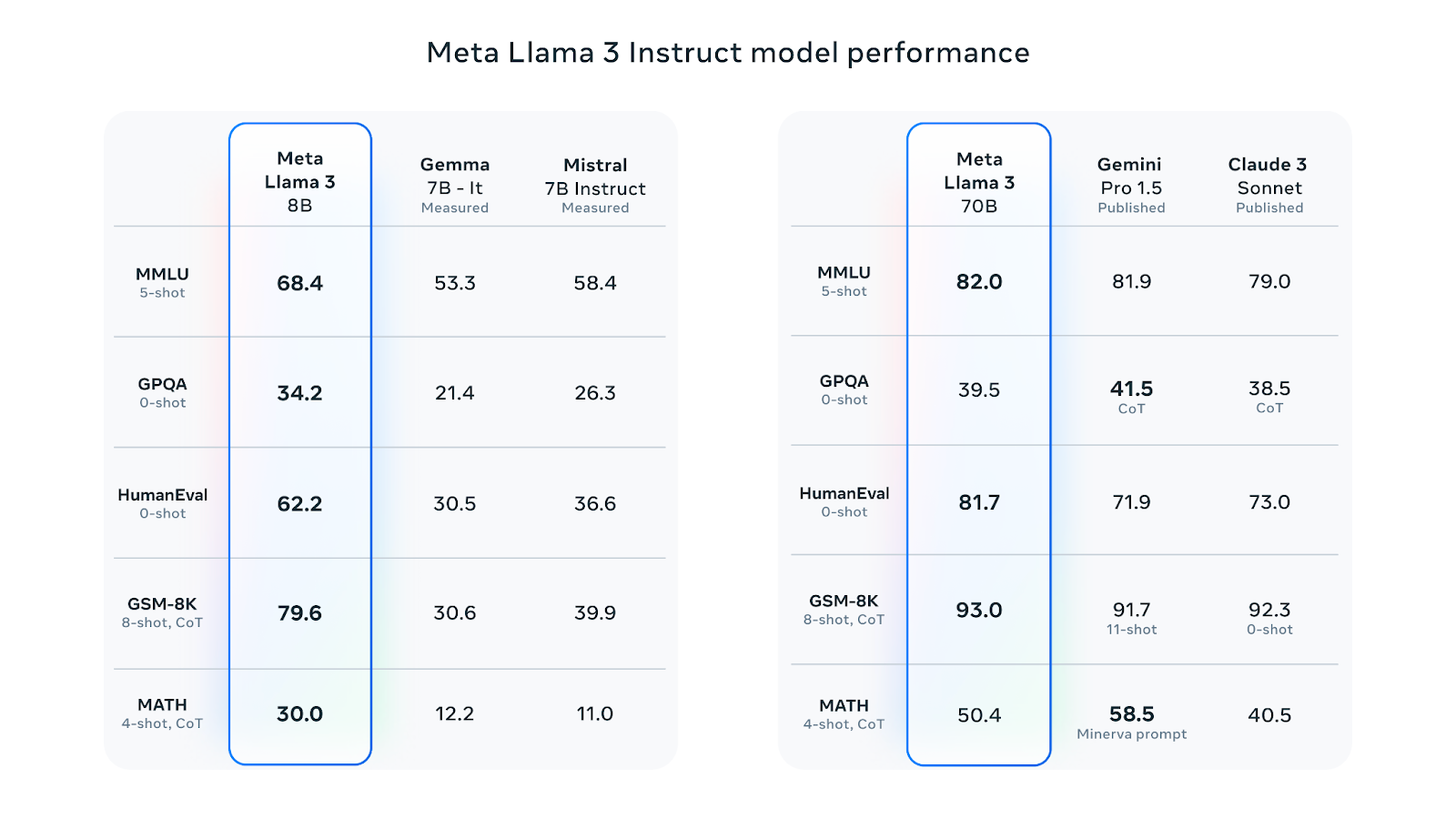
Meta just released the weights for Llama3 and it is one of the biggest releases thus far. There are two different sizes that are currently released, 7 and 70 billion parameters with a 405b on the way that is still training.
We still do not know all of the details from the changes of the architecture from last generation to this one but some important points are the following: bigger vocabulary at 128k tokens, bigger training run at 15 trillion tokens (7x bigger than llama2) and grouped query attention. These new decisions gave better results.
The current best open source model is given back to the Llama models. Even if it seems too good to be true, the good part is that we have the LMSYS leaderboard that tells us which model people prefer. It seems that even here it still shines.
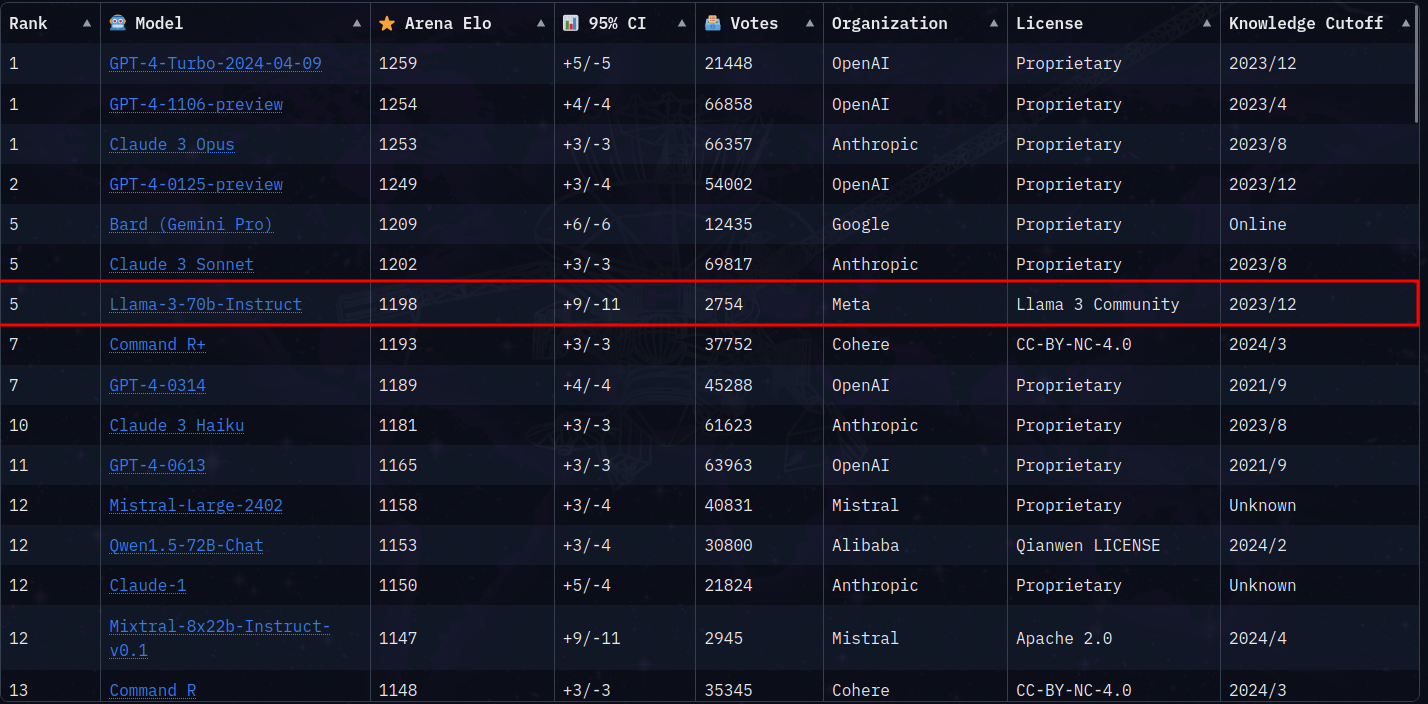
GPT-4 is still the king of the current leaderboard but it is amazing that Llama3-70B can be on the top 5 and is winning against previous versions of GPT-4, smaller versions of Claude3 and Mistral large doesn’t seem to be that big. Even Llama3-8B is in 14th place currently.
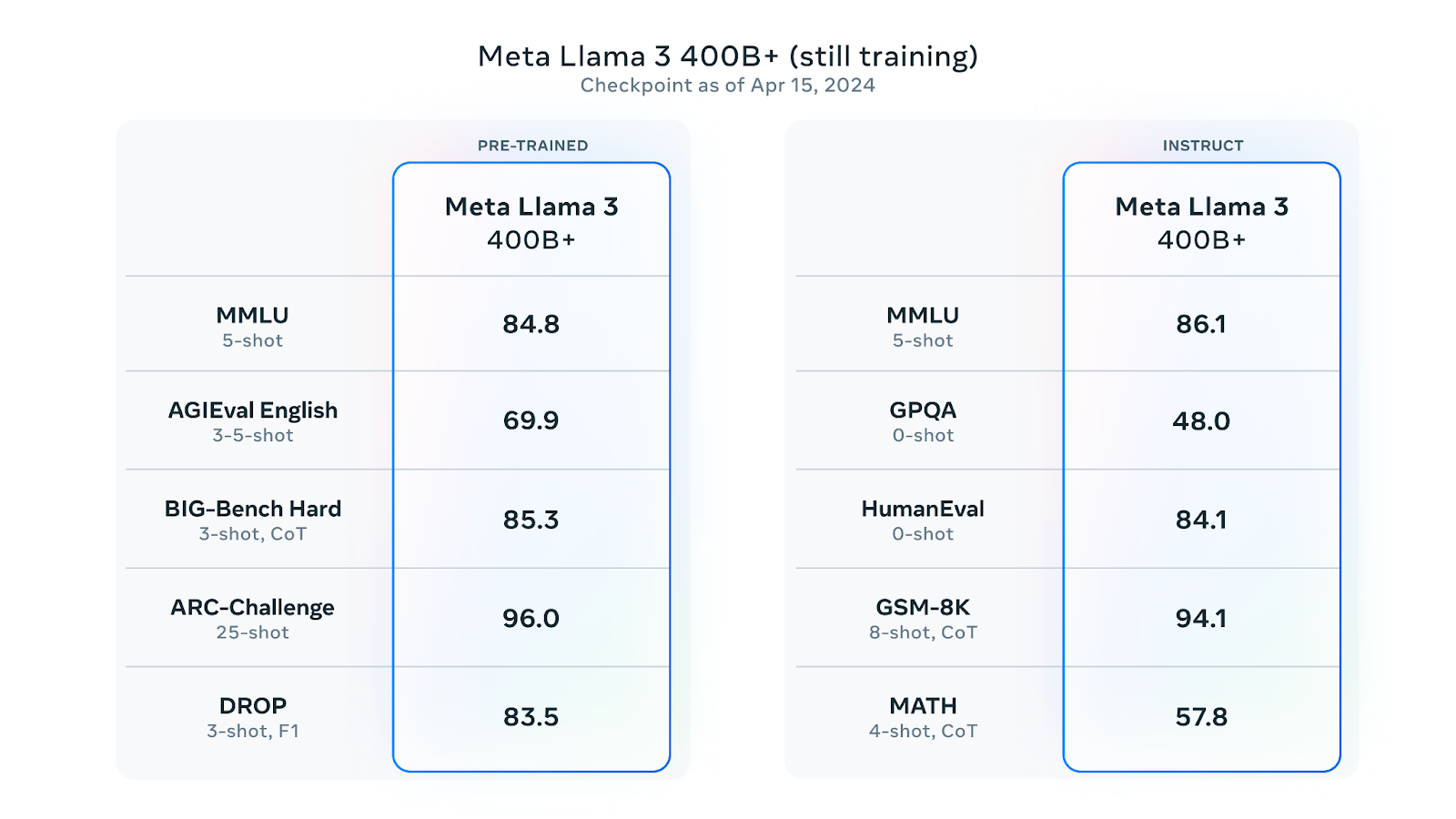
Finally, there is another model still training that is going to be 405B parameters big and it is going to rival or even top at the end of the training against GPT-4. To see the throne of OpenAI so shaken in the last couple of months makes me think that they still have an ace behind their sleeves. Let’s see what happens with the new version of GPT.
If you want to play around with the models, it is currently on ollama in here and if you would like to read the release blog post it is here.
Does Transformer Interpretability Transfer to RNNs?
Understanding language models is still a difficult task. Now that we have alternatives to transformers like RWKV and Mamba, can we apply these same tools to them? Researchers at Eleuther answered this question, and we know that yes, we can.
They tested three different interpretability tools to see if we could understand non transformer based language models. Contrastive Activation Addition (CAA), the tuned lens and “Quirky” models.
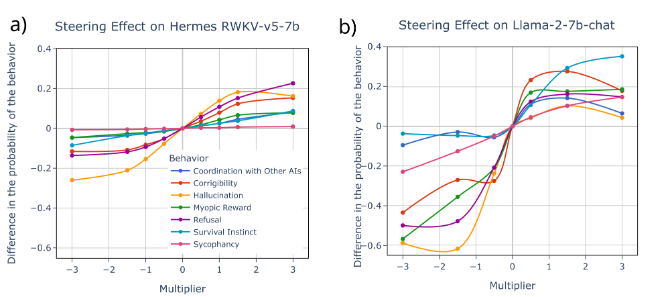
Contrastative Activation Addition is to modify the language model using “steering vectors” generated on the average of responses from the model to stimulate a specific behavior. As we can see in Figure 4, you can steer the models as you could with Llama.
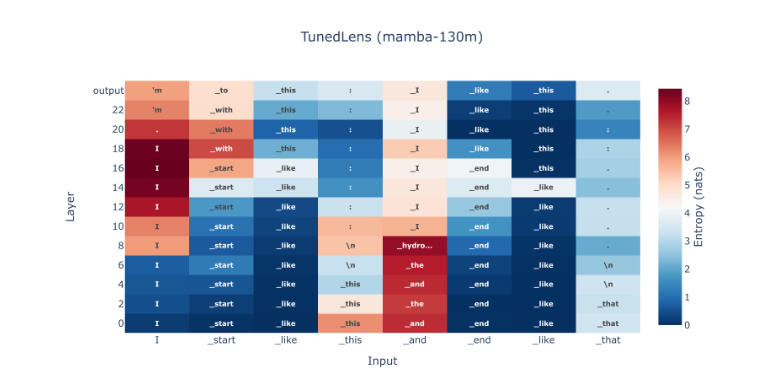
The tuned lens is a way to tell which token is going to be predicted by a language model and the deeper you go on poking these models with a linear probe, the more easily you can make it predict the next token.
Finally, quirky models are LMs that can give the right answer even if they are fine tuned to give the wrong answer.
If you would like to read more about this you can check it out in the paper here.
That’s all for this week! See you next week.