

Welcome to Research Log #035! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
NEKO
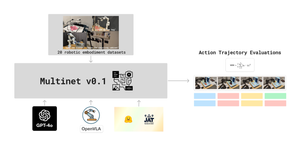
The NEKO Project aims to build the first large scale, Open Source "Generalist" Model, trained on numerous modalities including control and robotics tasks. You can learn more about it here.
Datasets: As we make progress to a pretraining corpus, we have been working on getting the Captions and VQA datasets ready. First, Eric got some example tiny datasets working and you can find them on huggingface here. We have also made it possible to stream the VQA and Captions datasets as a single entity, and we are now working on an API that is easy to use so that all the different VQA datasets have the same interface. More can be found on the github for our benchmark here.
Pulse of AI
Last week, we were mainly focused on the return of the Recurrent Neural Networks (RNNs). We saw a lot of releases related to RWKV with two new versions, and a new paper from Google DeepMind that introduces a new RNN model based on their Griffin architecture.
Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence
Eagle (RWKV-5) and Finch (RWKV-6) are new architectures from the RWKV Project, they released two new architectures with a 1.2 trillion token dataset that was used to train the family of models that goes from 0.46 to 7.5 billion parameters.
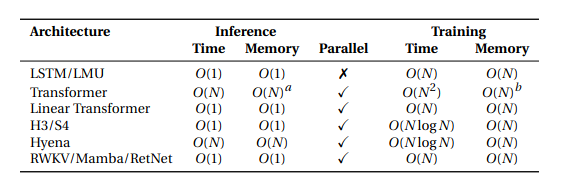
RWKV is a modern take on the old idea of RNNs, specifically it is more aligned to LSTMs. This new version of RNNs seem to be as capable and scalable as transformers and the cool part is that they are incredibly efficient. Normally, you train a transformer in O(n²) but RWKV with this new update is as efficient as Mamba or RetNet.
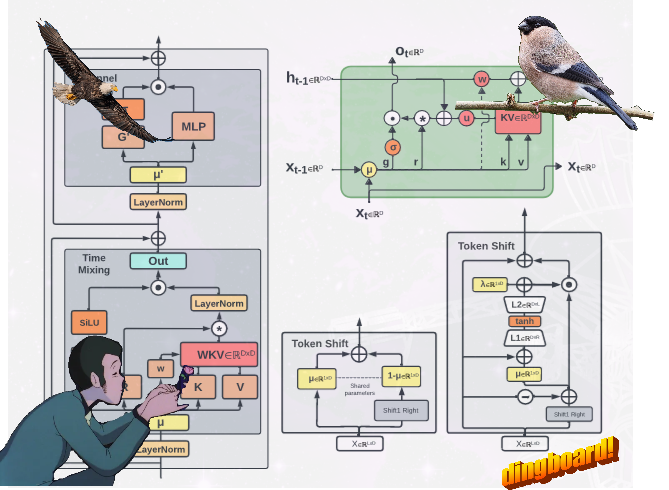
The new architectures are similar to RWKV-4 but have some fundamental differences. They reduced Time Mixing from 4D to 3.5D because they have a new gating mechanism in the mixing channels. More interestingly, on the finch architecture they made a token shift that makes “the amount of new and old data allocated per channel now dependent on the input at both current and prior time steps”. Another important thing is the Finch Time Mixing module can change over time depending on the data and is not related to a learned parameter. This seems to make an overall improvement from the last version of RWKV.
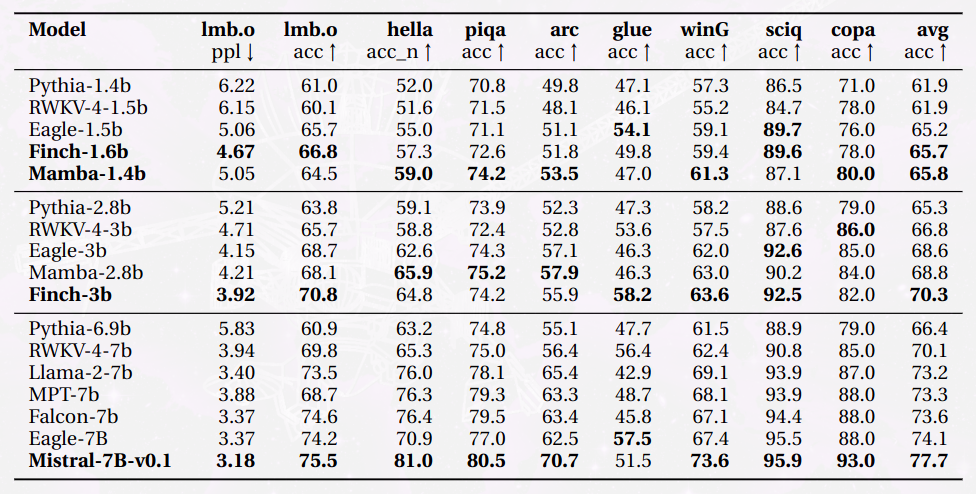
The new model seems to be around the same category as Mamba and it is nice to have an alternative to Transformers, although Mistral is still dominating in the 7-B range.
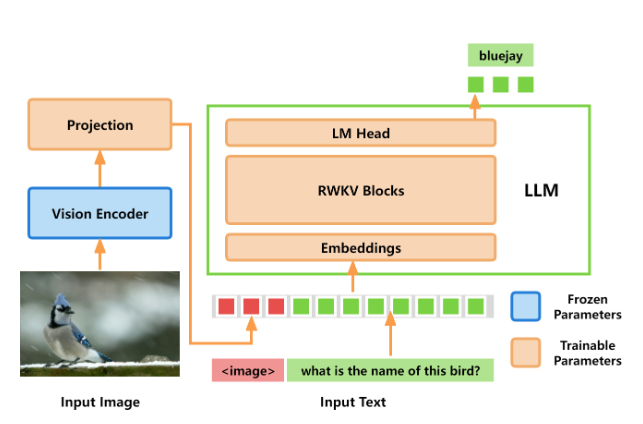
There is an entire paper about Vision-RWKV and it can be found here. But I wanted to touch on that time and time again, the general idea for what we see in vision is just a vision encoder on top of the language model blocks. The Language Model basically learns new “vocabulary” from the vision encoder. We could see the same idea on AnyGPT and on Fuyu.
I still remain fairly optimistic about RWKV because it is steering the conversation about alternative architectures that are worth a shot. RWKV with Mamba are finally giving us new architectures that are potent.
If you would like to read the paper, it is here, the code is here and finally the weights are open source and they can be found for eagle here.
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
Recurrent Gemma is a new release from Google DeepMind that uses the Griffin with slight tweaks to make it performant against the transformer counterparts.
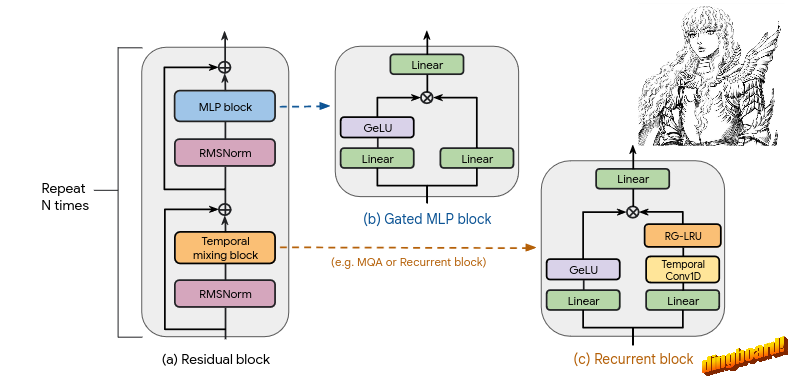
The Griffin architecture has two main components, a temporal mixing block with a gated MLP block. It is fairly similar to how RWKV works, although a bit simpler. A common denominator from all of these architectures is the MLP block, if it ain’t broke, don’t fix it.
The main difference from Griffin to RecurrentGemma is that they added an idea from Gemma that was to multiply the input embeddings by a constant equal to the square root of model width. This makes RecurrentGemma a fair competitor to Gemma.
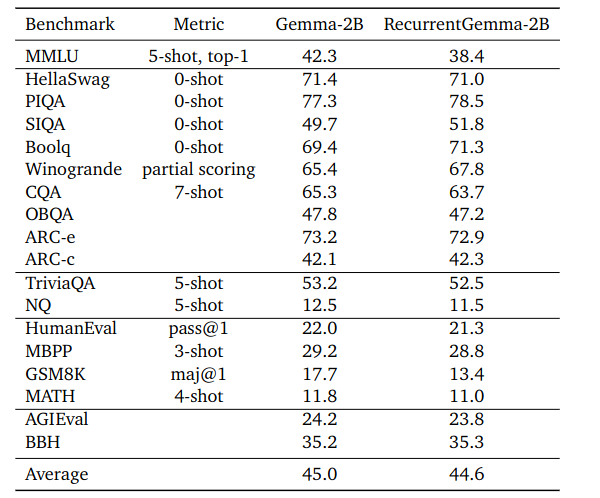
It seems to compete fairly well, but let’s not muddy the waters here, we literally just talked about RWKV, so let’s do a bit of a comparison against it.
* I used the average of Arc-e and Arc-c because RWKV doesn't have the distinction.
So, as we can see, Recurrent-Gemma-2B is slightly better than Gemma and RWKV is lagging a bit behind. But, we are talking about a place where we can see RNNs taking on the lead to transformers. And let’s be real, the Winogrande benchmark was only partially scoring for Gemma and RecurrentGemma.
If you would like to play around with Recurrent Gemma, it is available through gemma.cpp in here, the paper is here, and the weights are open source and are in here.