Welcome to Research Log #034! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
NEKO
The NEKO Project aims to build the first large scale, Open Source "Generalist" Model, trained on numerous modalities including control and robotics tasks. You can learn more about it here.
This week was focused on datasets, to debug bigger training runs. We started working on building the dataset for pretraining the model, and we have also been generating some smaller versions of the datasets that we are going to use for debugging purposes. If you would like to help on either NEKO or our pre-training corpus, here is the github and the discord server.
Pulse of AI
This week, researchers are really focusing on making the training of Large Language Models cheaper by using compression. They are also trying to make LLMs think harder on some problems than others and finally a new LLM release rivals GPT-4.
Training LLMs over Neurally Compressed Text
How could you make an LLM have a bigger context window and make the training use less compute without doing any change to the actual transformer architecture? Researchers at Google DeepMind and Anthropic recently answered this question by training a Language Model (LM) using only neurally compressed text.
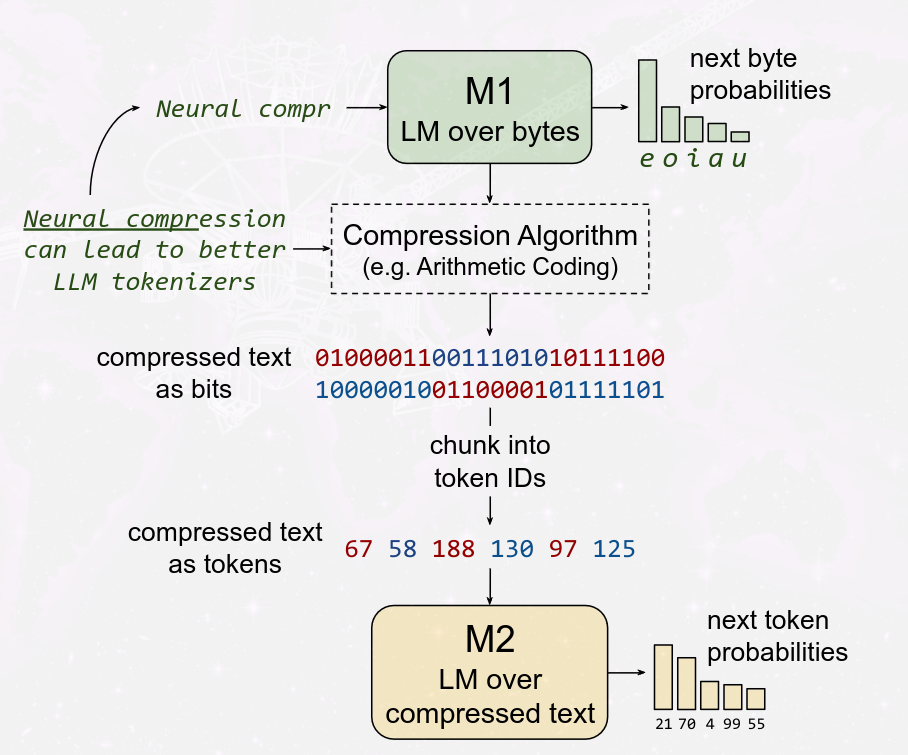
The best method for compression that we currently have is using Language Models to generate these byte probabilities and compressing them. So even if traditional methods like zip, gzip, or 7z seem good, check out the Large Text Compression Benchmark (LTCB) where the top results are a mixture of neural networks and heuristics with the likes of NNCP (Transformer), CMIX (LSTM+heuristics) and tensorflow-compress (LSTM). Even more recent work like Language Modeling is Compression that achieved super high compression rates using Large Language Models.
Conceptually, this paper is about a way of training a tokenizer for a LM. The way that this works is that you have two different Language Models M1 and M2. The first one is trained to predict the next byte probabilities and it uses Arithmetic Coding (a compression algorithm) to generate compressed bits of text. With this compressed text, they chunk up the encodings and try to predict the next token based on the compression results from M1.
Why is this important? Three main reasons: First, you can make the LLM understand a bigger context because you can compress the text a lot more, they achieved a 5.3x compression rate overall, second, you have better efficiency because the context window of transformers is O(n²), and, third and last, you have a single and very potent way of allocating compute for harder tasks because the first model can compress more or less depending of the amount of perplexity seen in the text.
If you want to read the full paper, it is currently on Arxiv here.
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
There is still a problem in making different tokens harder or easier to be computed in Large Language Models. Transformers naturally just use the same amount of compute for the next token. But, you can change this, for example, you could generate trains of thought like what they did on Quiet-STaR or maybe use Neurally Compressed Text, but the way researchers at DeepMind solved this is by creating a new architecture named Mixture of Depths (MoD) and mixture-of-depths-and-experts (MoDE).

MoD works by allocating a specific compute budget for the overall computation. The key difference between MoD and mixture-of-experts (MoE) is that they route through different blocks instead of using different experts you only route through different blocks. Besides that, you can basically “skip” a block by using Residual connections so that the model can understand when it is appropriate to actually do the full computation. The good part about this architecture is that you still can use it with the usual mixture-of-experts.

The mixture-of-depths-and-experts (MoDE) is the amalgamation of using MoD and MoE to have a brain child that works amazingly well. The FLOP for the buck is better than the usual baseline and when you use MoDE the results are pretty good.
If you would like to delve deeper, the paper is here.
Command R+
Cohere launched the new model Command R+ on their series of R models. This new model is specialized on Retrieval Augmented Generation, tool usage and is trained on 10 languages. It’s a pretty chunky model at 104 billion parameters and joins the pantheon of LLMs that are too big to run on local computers but are a good next step along with DBRX and Grok.

This LLM seems to be comparable against GPT4-turbo and Mistral-Large. Although, the best part about this model is that it is pretty cheap. It too is pretty good at citing, something that if you are an enterprise really want.
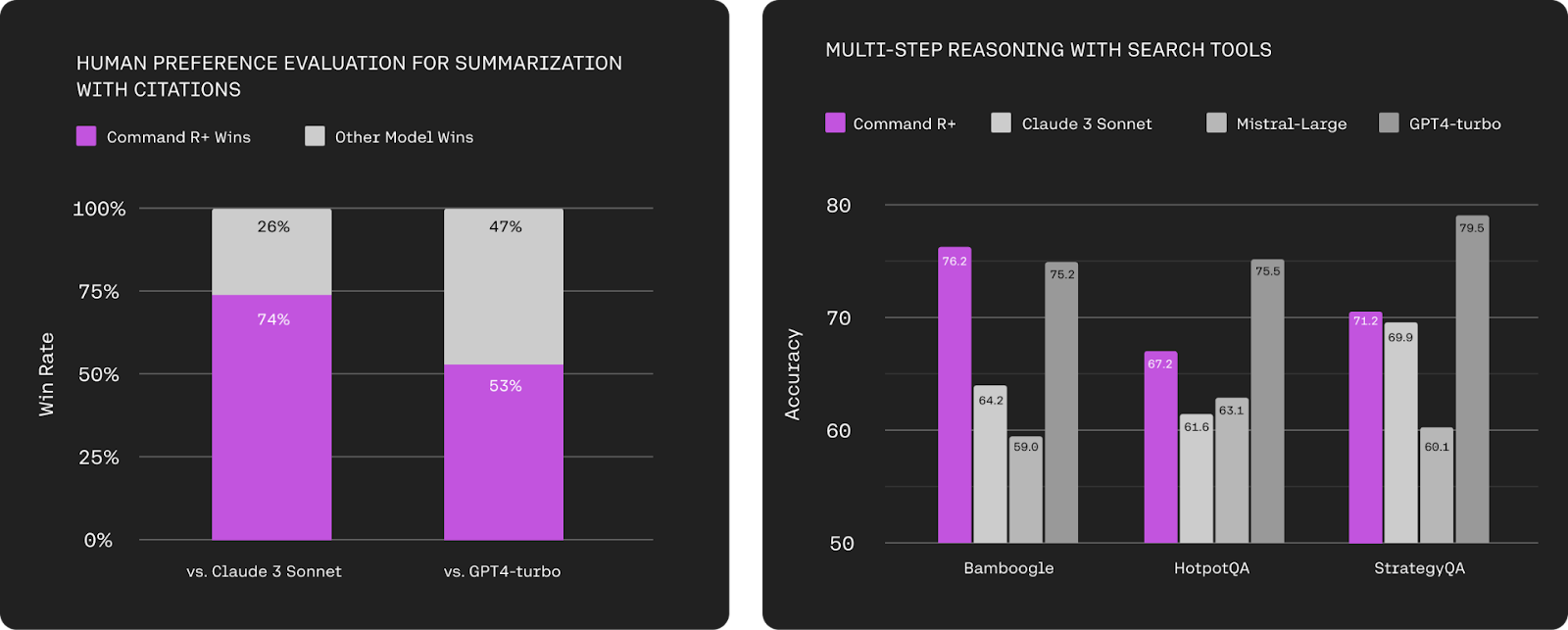
Right now, it seems to be winning against the smallest version of Claude 3 and GPT4-turbo. But, I think that for the pricing, it makes sense that it is comparable to those models.
Cohere seems to be aiming itself to be an enterprise solution and not a consumer one. But, they seem to be aiming to be part of the AI gauntlet of companies that work with Microsoft because they are releasing the model first through the Azure API.
If you would like to read more in depth about the launch of Command R+, the release blog post is here.
That's it for this week, I hope you have an amazing next week!
If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, Linkedin, and Mastodon!