Welcome to Research Log #031! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
NEKO
The NEKO Project aims to build the first large scale, Open Source "Generalist" Model, trained on numerous modalities including control and robotics tasks. You can learn more about it here.
VQA: Typically, when a model is trained, the perplexity metric of the model decreases. Perplexity is the measure of model uncertainty, however the NEKO model perplexity remains the same during training. The team is addressing this issue in the Visual Question Answering modality.
Datasets: In Research Log #030, we mentioned that the team is working on benchmarking several large open source models. We are now creating the data loaders for testing those models on our benchmark. If you would like to help, send a message to the discord server!
Agent Survey
The Agent Survey is an effort to comprehensively understand the current state of LLM based AI-Agents, compare to formalizations of AI agents from other areas like RL & Cognitive Science, and identify new areas for research and capability improvements. We’re running this as a community survey, so if you’d like to get involved, check out the roadmap and join the discord channel!
The Agent Survey team has entered its final sprint for v0 of the Survey. Almost there! If you would like to get into the conversation, join the discord here.
Pulse of AI
This week a new method for stealing parts of an LLM was released, Apple created a new Multi Modal Model that achieves State of the Art in Visual Question Answering, and Google has created a new model capable of impersonating someone with just a single image.
Stealing Part of a Production Language Model
We all know that the best models currently are closed source. They are black boxes inside of the servers of OpenAI, Google and Anthropic. But what if you could steal these models? Researchers at Google DeepMind / ETH Zurich / University of Washington / OpenAI / McGill University have created a method to get the embedding projection layer of an LLM for less than 20 dollars.

This attack works top-down working from the projection layer. The way they did this is by learning the logit probabilities, which are the probabilities of certain certain word choices.
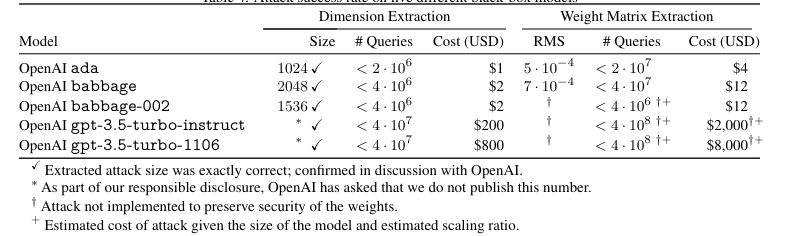
The results of this research are that we now know the sizes of GPT-3 models ada, babbage and babbage-002. I do not think it scales linearly, but it is interesting that we can learn this much just from logits.
There are several ways to mitigate this type of attack, you can prohibit API access to the use “of both logit bias and logprobs at the same time … either alone being allowed”. Check for malicious queries, add noise to the logits and rate limit the amount of logits you can get.
If you want to read more about how to steal secrets from a company in an academic setting, you can read more here.
MM1 Methods, Analysis & Insights from Multimodal LLM Pre-training
Apple has trained a new state of the art MultiModal Large Language Model and they have released their findings in a new paper. This new family of models is called MM1, and they are a mixture of experts that range from 3B parameters in size up to 30B parameters.
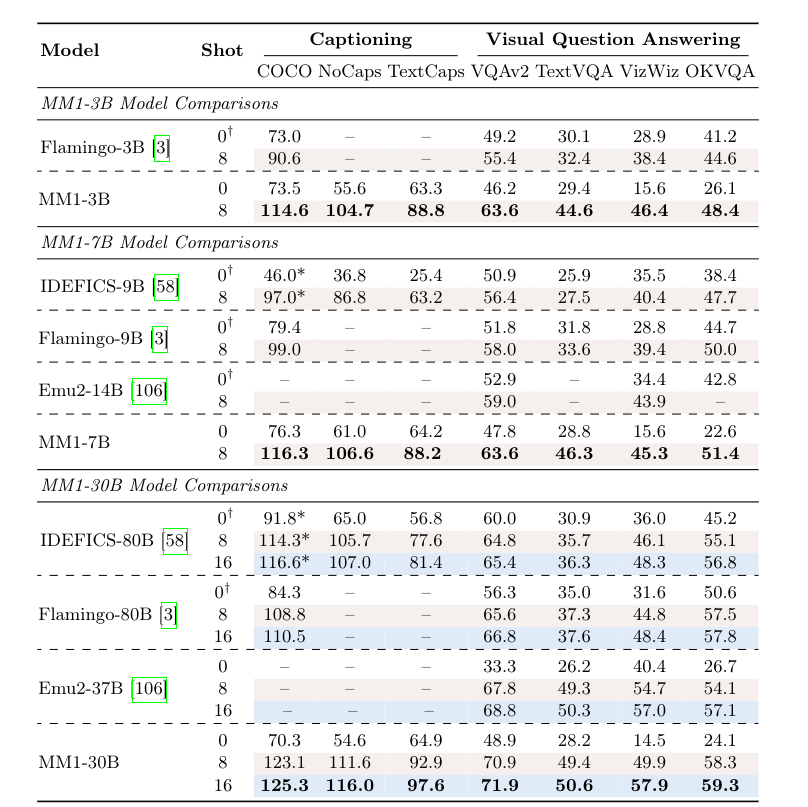
The models pack a punch. Currently, the 30B model wins against models like IDEFICS-80B that are almost 3 times as big.
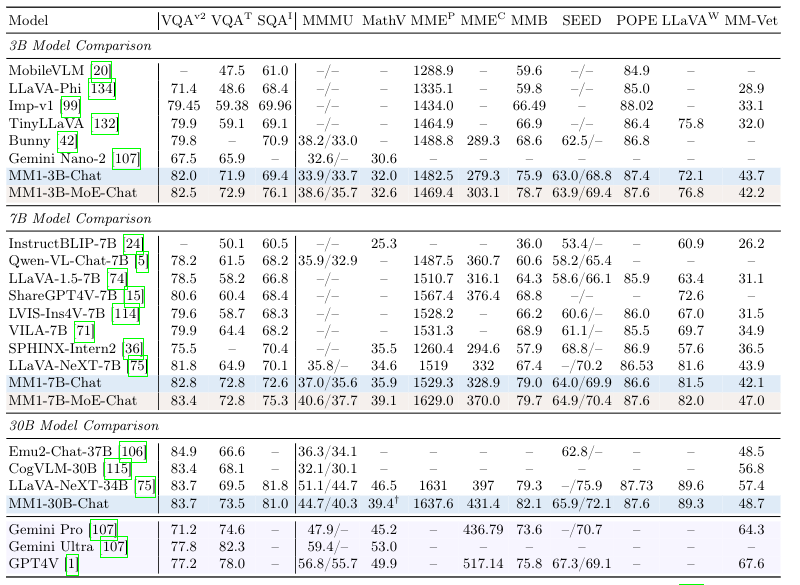
Once fine tuned for chatting, the results of the models in Visual Question Answering consistently outperform against models of the same size. I think that these models are going to be used for something Apple is cooking for the next generation of iPhones.
If you want to read more about the new MM1 models, you can read here.
VLOGGER

Researchers at Google have created a new diffusion model that based on a single image can generate audio and video of a person talking without specific training for the person.
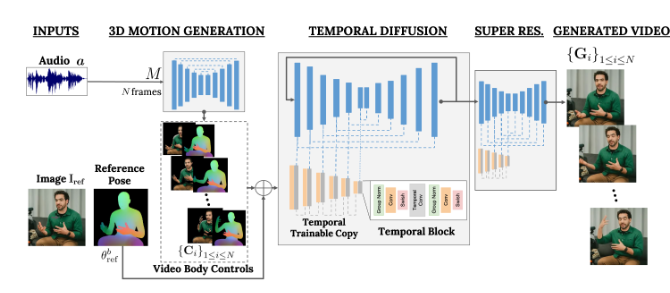
The way that VLOGGER works is that it accepts audio and generates reference poses based on the images that match the audio. Now, with the reference images, they are given to a temporal diffusion model and later on to a super resolution model to generate the final result. These super-resolution models are trained to generate a sequence of photorealistic movements.
These new models seem to be mixing in more and more parts, building on top of each other and generating pipelines that are going to be super useful in the following years. If you would like to read more, the paper is here and the main page has some interesting demos here.
If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, Linkedin, and Mastodon!