Welcome to Research Log #028! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting in the Pulse of AI!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
NEKO
The NEKO Project aims to build the first large scale, Open Source "Generalist" Model, trained on numerous modalities including control and robotics tasks. You can learn more about it here.
- VQA: We are currently looking at scaling up the amount of images the image branch supports. If you would be interested in helping, check out the github here.
- Dataset: Now that we have a dataset list, we are compiling a list of models to benchmark on the different tasks. If you would like to get involved, please reach out through the discord!
Agent Survey
The Agent Survey is an effort to comprehensively understand the current state of LLM based AI-Agents, compare to formalizations of AI agents from other areas like RL & Cognitive Science, and identify new areas for research and capability improvements. We’re running this as a community survey, so if you’d like to get involved, check out the roadmap and join the discord channel!
The team has finished the survey and the outline, and is now moving into the drafting phase. During the investigation, we found that LLMs tend to be narrow in the scope of their actions. In our Tool Use Models project, we want to strive for more generalist capabilities.
Tool Use Models
The Tool Use Model Project is an effort to build an open source large multimodal model capable of using digital tools. We’re starting with exploring the ability to use APIs. Get involved with the project on discord!
The Tool Use Model team has identified multimodal processing as a key next step for the project, like the Fuyu architecture. Additionally, as part of the push for more generalist capabilities to cater to a wider range of users, the team is aiming for wider coverage of APIs in the API database. This project is moving rapidly, expect more updates in the coming weeks!
Pulse of AI
This week we saw a new text to video model that maps onto concepts, rather than pixels. A new and updated model from Google that has a context size of 10 million tokens and is capable of accepting video. One of the biggest collaborations for the creation of a dataset with nearly three thousand participants from 119 countries. Finally, a more efficient architecture for text to image generation that improves on previous results.
Sora

There is a new model in the text to video space that beats state of the art by a lot. OpenAI released a new model called Sora. The purpose of Sora is to be a world simulator and one of the side results is that it is capable of producing high fidelity clips of around one minute. With this new release, OpenAI has released a new technical report.

They passed from video to image patches, you can think about “patches as tokens for video”. They managed to scale up transformers to be capable of accepting video. Another key idea was to train on native resolution of videos so that there was no information loss. Training on native resolution seems to improve framing capabilities of the model.
The Sora model is capable of the following: animating images from DALLE, extending generated videos, video to video editing, connecting videos, etc.
An interesting result from the research from OpenAI is that it is capable of being a 3D simulator of sorts. It can accurately predict the perspective of different places. If you want to dig deeper, the technical report is here and the release page is here.
Gemini 1.5
Google Deepmind has released the half point for their flagship models, Gemini 1.5. Gemini 1.5 seems to be capable of a lot of what was promised with the original Gemini, it has an insane context window of 10 million tokens. 10 million tokens is roughly equivalent to 700k words. Gemini 1.5 now seems capable of accepting up to 1 hour of video.
The technical report is a little bit loose with the architecture they are using, but we know it is a Mixture of Experts using Transformers. This new model supports multimodal input, in one go, it is capable of accepting video, audio and text.

It seems that this version of Gemini is capable of retrieving perfectly in context of up to 10 million tokens. They generated secrets for every thousand tokens and asked Gemini and GPT-4 to retrieve it. Gemini was capable of going up to 10 million tokens with basically 5 errors in total.

Gemini 1.5 is capable of translating from a language that was not seen in its training data. With enough context, this model is almost as capable as a human. Finally, they won over a lot of the classic benchmarks like Hellaswag, MMLU and HumanEval.
Google seems to basically be dethroning OpenAI from its capabilities with this new release. Now, the competition is going to get a bit more fierce. If you would like to delve deeper, the technical report is found here.
Aya Dataset
Aya is “the first human-curated open-source, multilingual instruction-style dataset” from the community of Cohere for AI (C4AI). It took nearly three thousand participants from 119 countries to generate an amazing result. With languages that were normally under represented we now have an amazing dataset.

The way they collected this amount of information is by crowdsourcing it. The data collection was done in the Aya Annotation Platform. There is another part of the project called Aya Collections where other permissively licensed datasets were added.
If you want to read more, you can check out the paper here. The dataset is permissively licensed and can be found in huggingface here.
Stable Cascade

The Stability team has released a new text to image model based on the Würstchen architecture. This new model is easy to train on local GPUs for LoRA. The model is capable of super resolution, Inpainting/Outpainting and image2image tasks, it can even do text!. All of this, in an easier model to train.
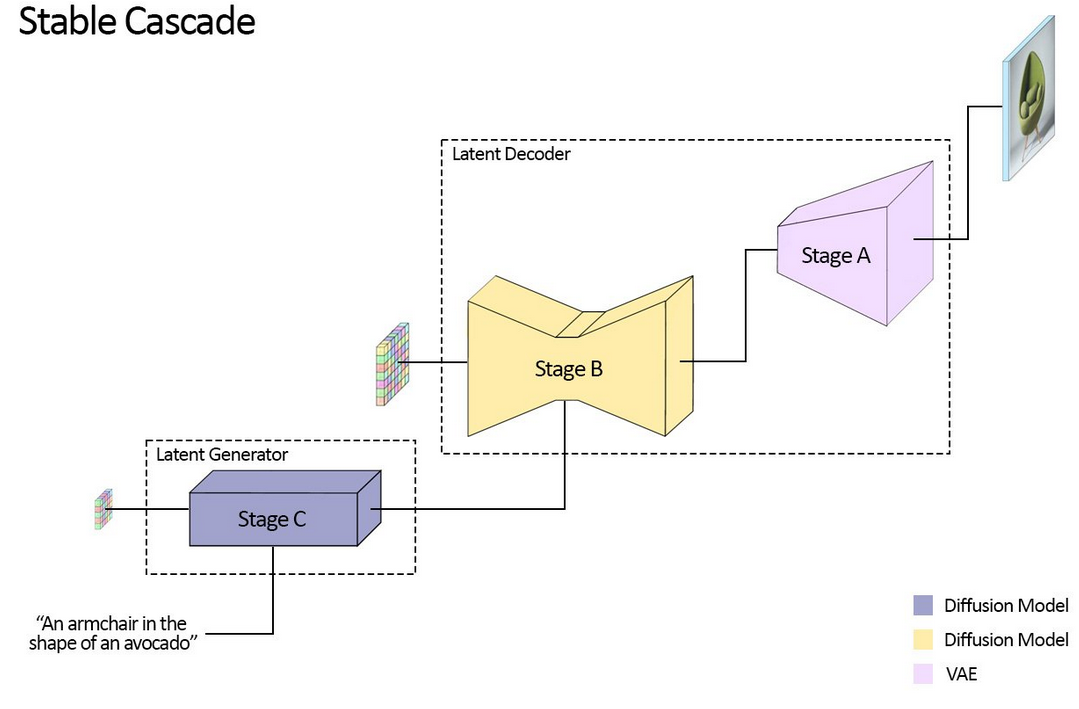
The Würstchen architecture consists of three different stages. First, at Stage C, the text is passed to 24x24 latents, the latents are used in the latent decoder to generate new images in Stage B and Stage A.
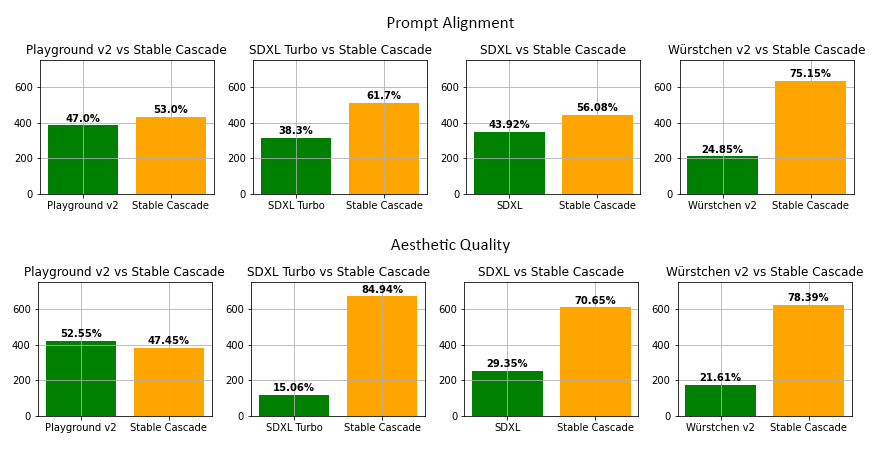
The new model is consistently better in Prompt Alignment and Aesthetic Quality. The results speak for themselves. The model is something similar to Midjourney.
If you want to read more, the release page is here and the code is open source and can be found here.
If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, Linkedin, and Mastodon!