

Happy Thanksgiving, & welcome to Research Log #019! We document weekly research progress across the various initiatives in the Manifold Research Group, and highlight breakthroughs from the broader research community we think are interesting!
We’re growing our core team and pursuing new projects. If you’re interested in working together, join the conversation on Discord and check out our Github.
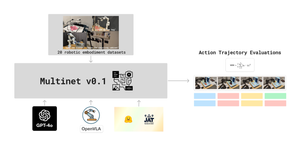
NEKO
The NEKO Project aims to build the first large scale, Open Source "Generalist" Model, trained on numerous modalities including control and robotics tasks. You can learn more about it here.
- Language + Captions + VQA: We have successfully integrated image captioning, VQA, language, and control into the main branch, and have demonstrated seamless training of all 3 objectives in a single run. This brings our code to a level of stability where we’re ready for larger multimodal experiments and scaling the NEKO architecture. To keep updated on technical details, check out the NEKO discord channel, and also the repository here.
Pulse of AI
There have been a few exciting
- White-Box Transformers via Sparse Rate Reduction: This paper asserts that popular deep network architectures, like transformers, optimize this measure, leading to the creation of CRATE, a white-box transformer-like architecture; experiments show CRATE's efficiency across large-scale real-world datasets, offering a promising framework that bridges the gap between deep learning theory and practice through a unified perspective of data compression.
- AYA: The AYA project by Cohere For AI is an initiative to bring people to collaboratively tackle the challenge of improving multilingual model performance by creating a high-quality multilingual dataset. They are still collecting more phrases, with a target of December 15th. Check the project out at this link!
- DiLoCo: Distributed Low-Communication Training of Language Models: DiLoCo presents a game-changing distributed optimization algorithm—a refined form of federated averaging—tailored for training language models seamlessly across devices with limited connectivity, offering a streamlined alternative to the intricate GPU-dependent cluster infrastructures typically required. If you are interested in creating an implementation of this. Join the discord and let us know! We are discussing if we should implement a version of this.
If you want to see more of our updates as we work to explore and advance the field of Intelligent Systems, follow us on Twitter, Linkedin, and Mastodon!